9.2. データグループの整列¶
データの整列とは,適当な標準試料によって決定されたエネルギーの絶対値に対して各データグループをエネルギーに対してシフトさせることを示します.ATHENA においては,そのような標準を任意に選択することができます.すなわち,単にグループリストにおける他のグループを利用するというだけです.整列は «Energy shift» パラメータを調整することによって行われます.
この調節は単純に «Energy shift» パラメータを手動で編集することによっても行えますが,以下に示すようにもう少し簡単に調節するためのツールが用意されています.
バージョン 0.9.18, で追加: エネルギーシフトの不確定性を示すためのコントロールが追加されました.この値は,メインウィンドウ中の «Energy shift» のラベルのコンテキストメニューから表示することができます.
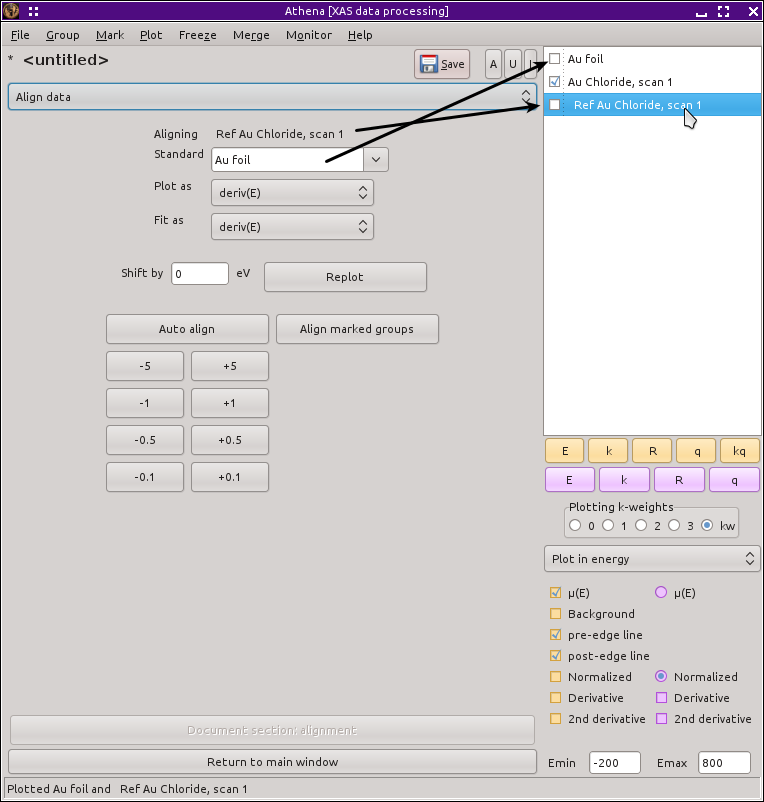
図 9.4 データ整列ツール
どのように整列するかあるいはどのように整列を可視化するかということについては,いくつかの方法があります.整列が行われると,μ(E), normalized μ(E), (次のプロットに示されているように,) μ(E) の微分,あるいはスムージングされた μ(E) の微分 としてプロットすることができます.スムージングされた μ(E) の微分を選択した場合は,3点スムージング関数が3回適用された μ(E) の微分 が表示されます.
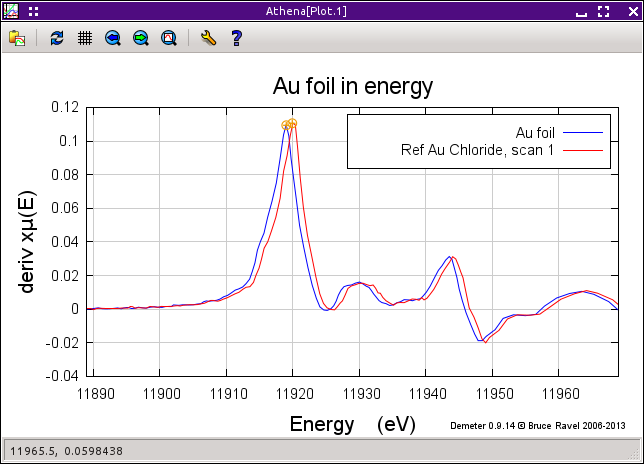
図 9.5 データ整列ツールを使っている時は,現在選択されているデータグループが標準に対してプロットされます.これによって,データがうまく整列されているかどうか視覚的に確認することができます.
データ整列は常に標準を固定したままで現在選択されているデータグループを動かすことでなされます.標準はツールの一番上のメニューから選択することができます.このメニューはグループリストにある,エネルギーに対してプロットできないデータ以外の,すべてのデータを含んでいます.
数字でラベルされたボタンをクリックすることにより手動で整列を行うことができます.これらのボタンで現在選択されているデータグループをボタンにラベルされた値だけエネルギー方向にシフトさせることができます.他には,«Energy shift» の現在の値を表示しているボックスの中にエネルギーシフトの値を入力することもできます.つまり,データがうまく整列されるまで,ボタンをクリックすることができます.
Auto align ボタンをクリックすると,データを標準に対して整列しようと単純なフィッティングを試みます.このフィッティングは吸収端から - 50 eV から + 100 eV の範囲で評価されます.フィッティングにおけるパラメータはエネルギーシフトと全体に対するスケール因子です.この機能により,標準スペクトルの一次微分と選択中のグループの一次微分の差が最小になるようなパラメータが求められます.エネルギーシフトされたデータはフィッティングのために標準スペクトルのデータグリッドに対して内挿されます.
このアルゴリズムは 5 - 10 eV ずれていても十分質の高いデータについては極めてうまく働きます.ノイズの多いデータについては,Fit as: のメニューからよりなめらかなデータについてフィッティングを行うようなオプションを選択した方がよいかも知れません.非常に大きくずれているデータについては,Auto align ボタンをクリックする前に,«Energy shift» に対して手動でおおよその値を設定する必要があるかも知れません.
一連のたくさんのグループに対して自動化された整列アルゴリズムを適用することもできます.まず整列したいデータ全てにマークをつけ,Align marked groups ボタンをクリックして下さい.いくつのデータについてマークをつけたかにもよりますが,ほんの少し待つと,運がよければ選択された全てのデータがきれいに整列しているはずです.
この整列アルゴリズムは列選択ダイアログで出てきた 前処理機能 で使われているものと同じです.
もし,データを 参照チャンネル とともに読み込んでいれば,このツールを参照スペクトルの整列に使うことができます.つまり,実際のデータを適切な絶対エネルギーに直すことができ,XANES スペクトルの吸収端エネルギーを比較する場合には特に重要です.
ご用心
データの整列をうまく行うことはとても重要です.ATHENA の多くの他の部分では,データの整列がうまくできていることを仮定しています.例えば,データのマージ や 線形結合フィッティングを行う場合には適切に整列されている必要があります.
データ処理の一般的なアプローチとして,私の場合は,はじめのスキャンを読み込んでそのデータを標準と見なします.はじめのスキャンの参照スペクトルに対して較正を行います.つまり,はじめのスキャンの参照スペクトルを絶対エネルギーに対して適切な位置に移動させます.ひとたび較正が終わると,一連の測定に関する残りのデータとそれぞれに対する参照スペクトルを読み込みます.そして,残りのデータの参照スペクトルを始めに較正した参照スペクトルに対して整列させます.データの質が十分高ければ,データの読み込みの際には前処理の機能を使うことが多いです.多くの場合,この手順で進め,自動化された整列が十分と信用して,マージやさらなる解析に対するデータを準備することになります.
DEMETER is copyright © 2009-2016 Bruce Ravel – This document is copyright © 2016 Bruce Ravel
This document is licensed under The Creative Commons Attribution-ShareAlike License.
If DEMETER and this document are useful to you, please consider supporting The Creative Commons.
