9.6. データのスムージング¶
データのスムージングを行うことは,大抵の場合よくないアイデアです.ノイズの多いデータを改善するのに最もよい方法は,試料調製や測定手順について考え直すことです.次によい方法は,測定を何度も行い,中心極限定理 の「魔法」に頼ることです.スムージングを行うことは,大抵の場合,見た目をちょっとよくする以上のことはなく,データに対してゆがみを入れてしまい,スムージング後のデータに解釈において,重大な系統的な不確かさを入れ込んでしまうという問題があります.
デフォルトのスムージングアルゴリズムは boxcar 平均であり,平坦で対称的な kernel をもつ一般的な線形フィルターとして実装されています.この kernel のデータ点の幅は指定可能なパラメータであり,奇数である必要があります.もし,このパラメータに 12 を設定した場合は,13 が使われます.
他には Gaussian フィルターを使うことができます.これも一般的な線形フィルターとして実装されています.この場合,kernel サイズと Gaussian における σを指定する必要があります.
スムージングの最後の選択肢は,IFEFFIT が提供する3点スムージングアルゴリズムを繰り返し適用することです.繰り返し回数はを設定することができ,他の2つのオプションで kernel サイズを設定することができます.
A Savitsky-Golay filter. is available when using LARCH, but not with IFEFFIT.
下図に示しているように左側にあるボタンを使って,スムージング前後のデータを重ね書きすることができます.もう1つのボタンは,スムージングされたデータを新しいデータとして生成するボタンです.
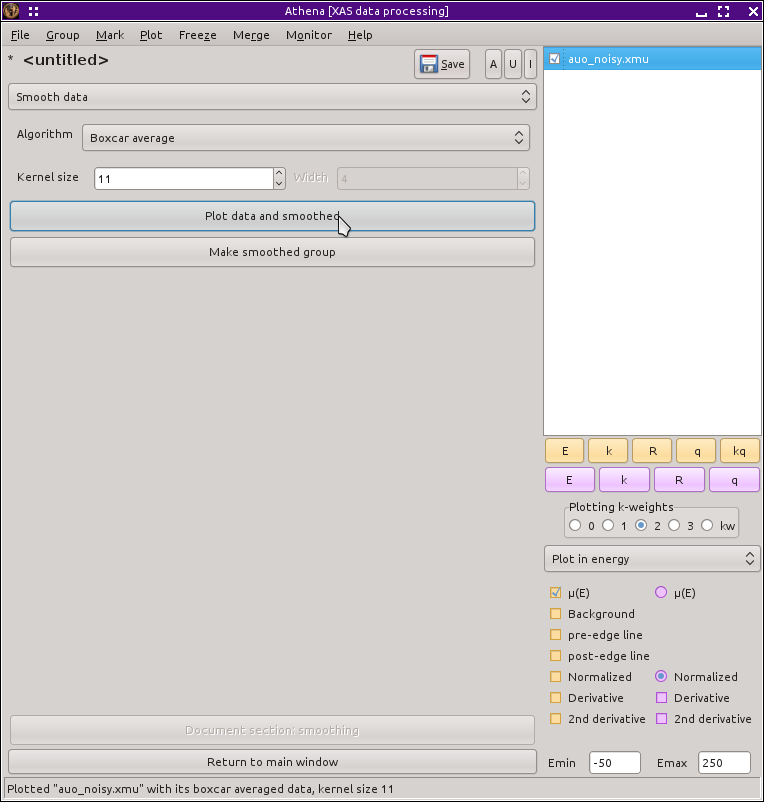
図 9.19 スムージングツール
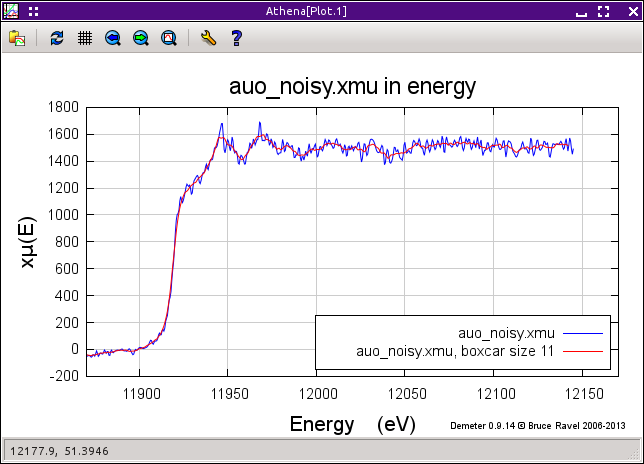
図 9.20 ノイジーな酸化金のデータを boxcar 平均を使ってスムージングしたところ
DEMETER is copyright © 2009-2016 Bruce Ravel – This document is copyright © 2016 Bruce Ravel
This document is licensed under The Creative Commons Attribution-ShareAlike License.
If DEMETER and this document are useful to you, please consider supporting The Creative Commons.
