12.1. 基本的なデータ処理¶
この処理済みの例ではデータの読み込み,較正,整列,マージとバックグラウンド除去とフーリエ変換について適切なパラメータの選び方を説明します.また,この例では3つの温度で測定した鉄箔のデータを扱います.
この例で使われているデータは,私の GitHub サイト で見つかります.ここには 60 K, 150 K, 300 K で測定した3種類の鉄箔のデータがあります.
初めに,60 K で測定された fe.060 を 読み込んで ください.これは比較的単純なデータファイルであり,エネルギーと I0 と It の検出器の信号を含んでいます.μ(E) データを得るために以下のように列を選択してください.
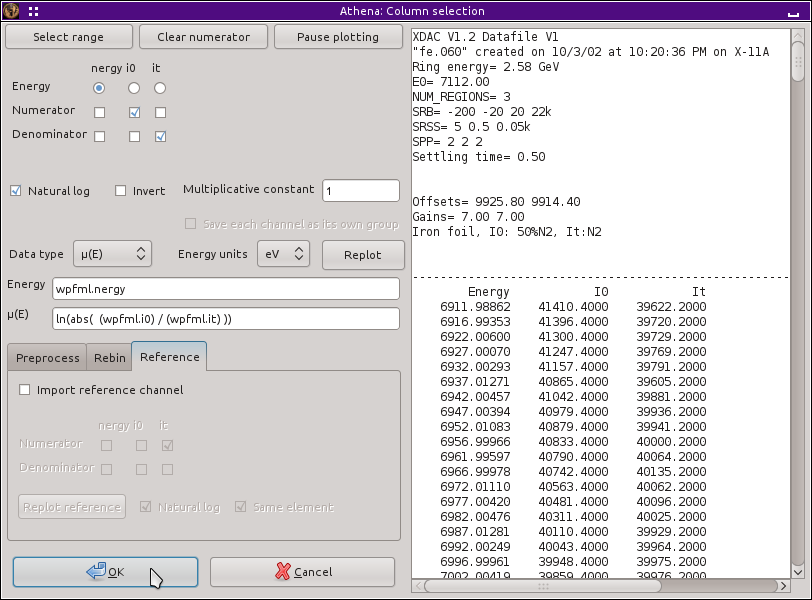
図 12.1 鉄箔について正しく選択された列選択ダイアログ
これらのデータを測定した際,ATHENA の較正ツールの使い方を説明するためのデータを得るために,意図的に分光器の較正を外しておきました.初めにしないといけないことは,つまり,これらのデータを正しく較正することです.
メインメニューから Calibrate energies を選択し,calibration tool を開いてください.下図の左に示すようにこれらのデータの μ(E) の一次微分がプロットされます.吸収端位置の選択は,小さなオレンジ色の丸で示されており,予想されるように一次微分の最初のピークの近いところにありリーズナブルなものです.分光器の較正は明らかに間違っており,オレンジ色の丸は 7105.5 eV にありますが,Fe K-edge の表の値は 7112 eV です.
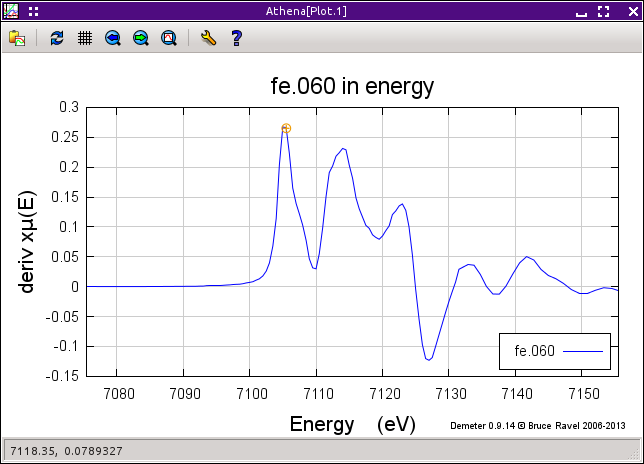
図 12.2 較正ツールでプロットされている鉄箔データ.μ(E) の一次微分
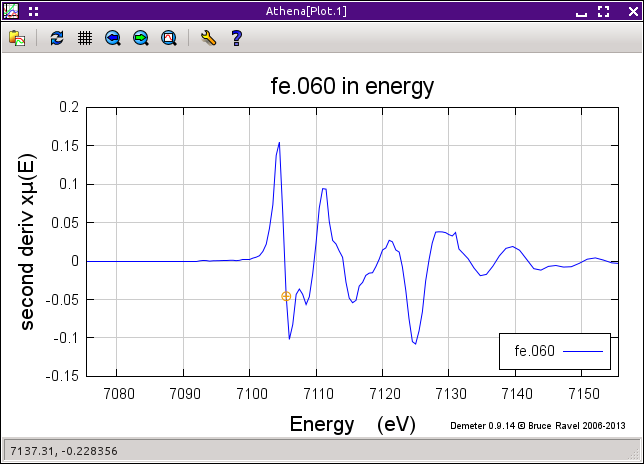
図 12.3 μ(E) の二次微分
一次微分のピークの点を 7112 eV に設定したいところです.単純に現在選択されている点 – つまり,ピークにかなり近い点を利用することができます.代わりに,Select a point ボタンをクリックして,プロットからピークにより近い点を選択することもできます.これを行うには,エネルギープロットタブ にある emin と emax の値を変更,再プロットしてピーク周辺のより狭い領域を表示するとよいでしょう.
3つめの一次微分の厳密なピークを高い確度で見つける方法は,display メニューから second deriv を選択して,二次微分をプロットすることです.データの二次微分を現在選択している吸収端位置と共にプロットしたものが上図の右に表示されています.
二次微分を表示すると,Find zero-crossing ボタンが有効化されます.このボタンをクリックすると,ATHENA は現在の吸収端位置近傍で双方向に y=0 となる点を探し,その点を新しい吸収端位置に設定します.この値はおおよそ 7105.3 eV です.Calibrate ボタンをクリックして,メインウィンドウに戻ってください.
再び表示されたメインウィンドウでは,2つのことに気づくと思います.«E0» の値は 7112 になっており,«eshift» の値はおおよそ 6.7 になっていると思います.ATHENA では,較正はこれら2つのパラメータを同時に設定することで動作し,選択された点が選択されたエネルギー値になります.
さて,60 K で測定された2つめのデータ fe.061 を読み込んでください.両方のグループにその小さな紫色のボタンをクリックすることで マーク をつけ,E ボタンをクリックしてエネルギーに対してプロットしてください.
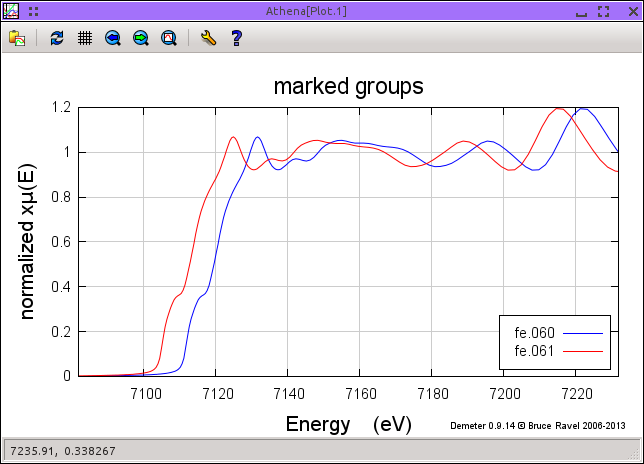
図 12.4 整列されていない鉄箔の μ(E) データ
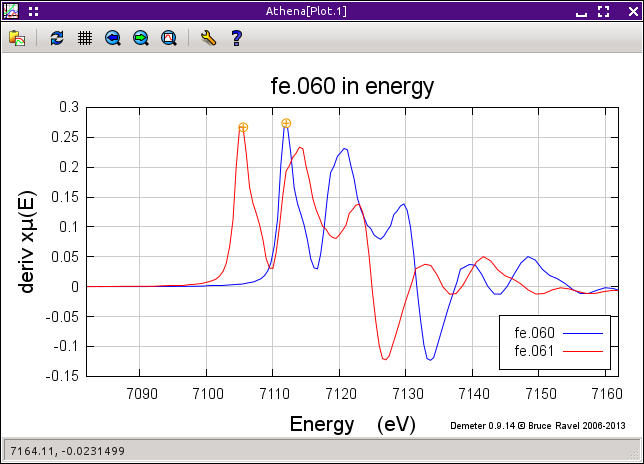
図 12.5 整列されていないデータの一次微分を整列ツールでプロットしたところ
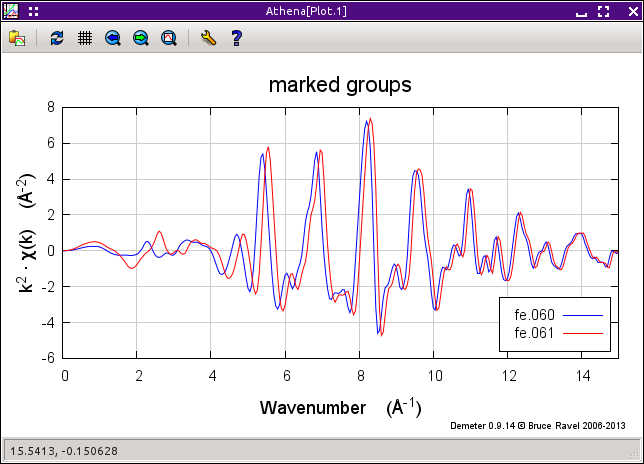
図 12.6 整列されていないデータを k についてプロットしたところ,«E0» は束縛されていない
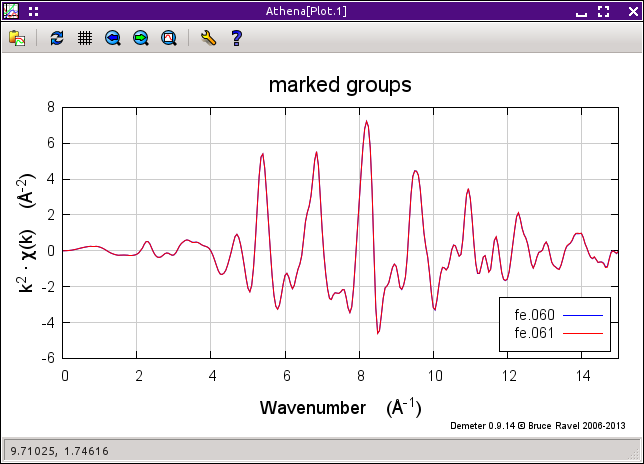
図 12.7 «E0» について束縛した後で k についてプロットしたところ.一旦,整列し,«E0» について束縛すると,これらの連続測定は十分つじつまが合っています.
上の図の左上には,整列されていないデータを示しています.同じ実験条件における同じ鉄箔に対する連続測定であるため,これらのデータは統計ノイズの範囲内で一致すると考えられます.これらが異なっているのは,2つめのデータがまだ較正されていないためです.
これを修正するには2つのステップが必要です.まず,メインメニューから Align scans を選択して 整列ツール を開きます.2つのデータが μ(E) の一次微分でプロットされます.リスト中の1つめのデータ,fe.060 は自動的に Standard メニューで選択されます.2つ目のデータはグループリストでオレンジ色に強調されており,Other として表示されています.
これらは非常にきれいなデータなので,自動整列アルゴリズムはうまく働くはずです.Auto align ボタンをクリックしてください.もしあなたのデータにノイズが多ければ,自動整列はうまくいかないかもしれません.その場合にはデータがうまく整列されたと考えられるところまで他のボタンを使ってエネルギーシフトを調整することができます.
メインメニューに戻ると,fe.061 の «eshift» パラメータがおおよそ 6.7 eV になっていることがわかります.エネルギーに対してプロットすると,データはうまく整列されていることがわかります.但し,k ボタンを押して k についてプロットすると,上の図の左下のように問題が残っていることがわかります.
fe.061 データは整列されていますが,較正されていません.つまり,«E0» パラメータがまだ fe.060 と同じ値に設定されていないということです.結果的に,データにおける2つのスペクトルの k=0 の位置が異なり,バックグラウンド除去後の χ(k) データが異なっています.
これを直すために,fe.060 の «E0» の値 – 7112 eV – をグループリストの fe.061 を  クリックした後にその «E0» テキスト入力ボックスに入力することができます. あるいは,グループリストの
クリックした後にその «E0» テキスト入力ボックスに入力することができます. あるいは,グループリストの fe.060 を選択し,«E0» パラメータを  右クリックして コンテキストメニュー を表示し,Set all groups to this value of E0 を選択することもできます.一旦,«E0» パラメータがこれらのデータセットで同じ値に設定されれば,上の右下の図にあるように2つの測定間で一致した結果が得られるようになります.
右クリックして コンテキストメニュー を表示し,Set all groups to this value of E0 を選択することもできます.一旦,«E0» パラメータがこれらのデータセットで同じ値に設定されれば,上の右下の図にあるように2つの測定間で一致した結果が得られるようになります.
次に,鉄箔について測定された残りのデータを読み込む必要があります.ファイル選択ダイアログを使って,複数ファイル読み込みの節 に書かれたとおりに残りのファイルを選択すると,以下のようになります.
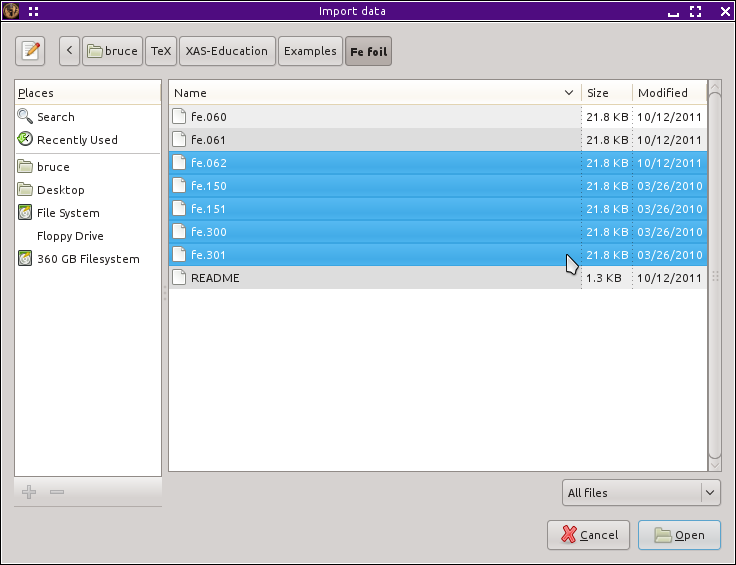
図 12.8 残りの鉄箔のデータの読み込み
Open button をクリックすると,これらすべてのデータが読み込まれ,グループリストに並びます.読み込んだあと,Alt-a と打つか,グループリストの上にある A マークボタンをクリックすると,すべてのグループにマークが付きます.最後に,グループリストから fe.060 をクリックして選択します.ここまで行うと,ATHENA は以下のように見えるはずです.
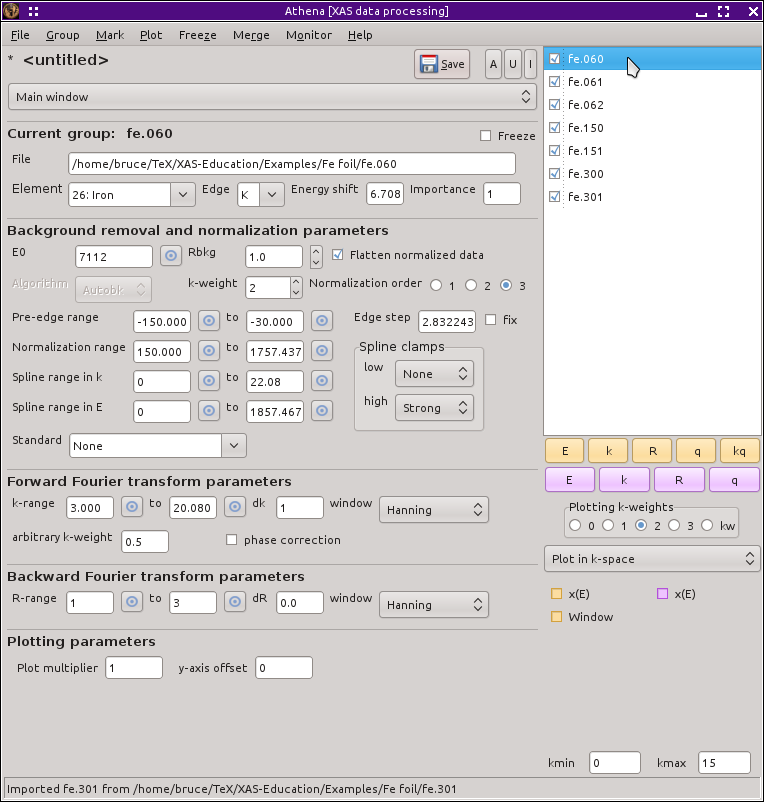
図 12.9 すべての鉄箔のデータが読み込まれ,マークが付けられたところ
この時点では,fe.061 のみが fe.0601 に対して整列されており,«E0» の値が適切に束縛されています.残りのデータに対しても同様にする必要があります.
残りの5つのデータの処理は,もしそれらを個別に行うとすれば大変面倒なものです.幸運なことに,ATHENA には大量のデータを扱う際に便利な多くのツールがあります.残りのデータを fe.060 に対して整列するためには,メインメニューから Align data を選びます.ATHENA はグループリストの最初のデータを整列の基準として選び,2つめを整列するためのデータとして選びます.これらの選択状況は上に示されています.
もちろん,fe.061 はすでに整列されています.グループリストの他のデータをクリックすると,まだ整列されていないことがわかるでしょう.残りのグループについて,それぞれを選択しては Auto align ボタンをクリックすることで整列することができますが,ちょっと面倒です.遙かによいのは,Align marked groups ボタンをクリックすることです.すべてのグループはよくそろっており,自動整列アルゴリズムがそれぞれに実行されます.
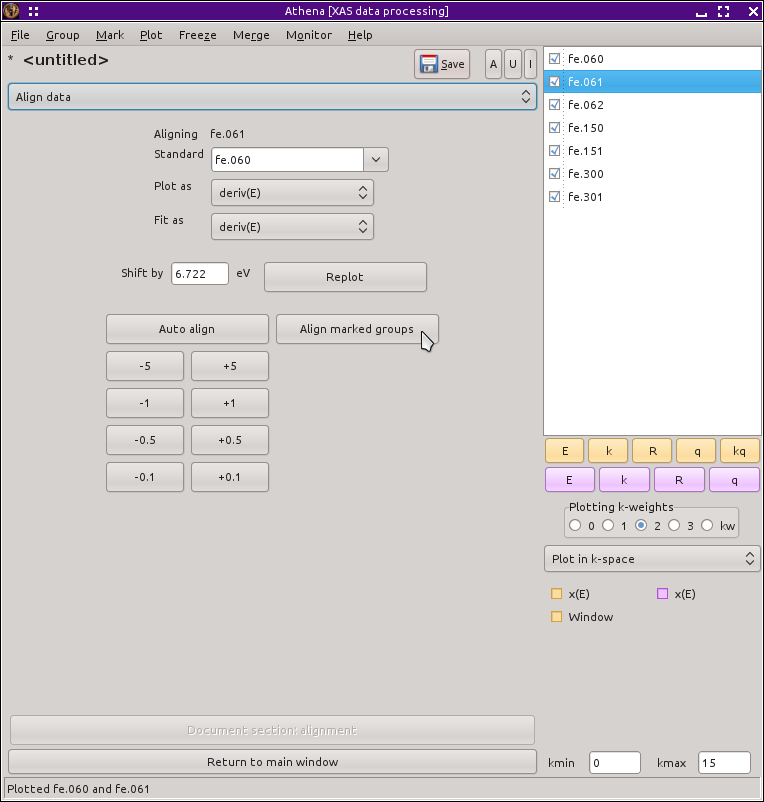
図 12.10 すべての鉄箔データにマークがつけられ,整列されようとしているところ
整列が終わると,グループをそれぞれを クリックして整列の質を確認することができます.これらはとてもよいデータであるため,自動整列アルゴリズムはうまく働くはずです.Return to the main window ボタンをクリックして,データ処理を進めてください.
それぞれのデータは整列されましたが,fe.061 だけが fe.060 と同じ値の «E0» を取っています.同様に,グループリストをクリックしながら,«E0» の値を編集するのはとても面倒に思われます.ここでは,«E0» コンテキストメニュー の Set all groups to this value of E0 の真の価値が発揮されます.
整列され,束縛されたデータの χ(k) を以下に示します.
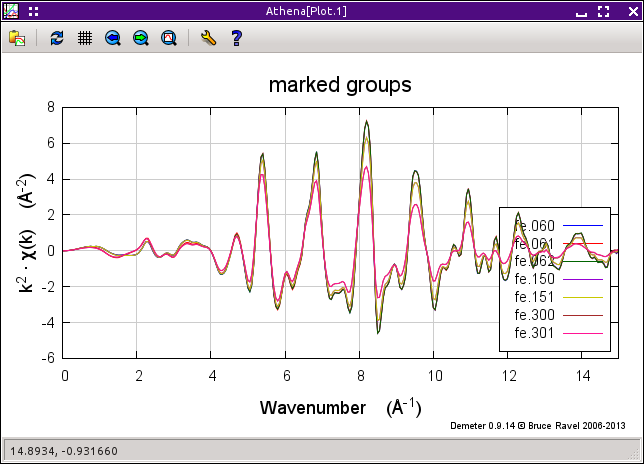
図 12.11 すべての鉄箔データの χ(k) スペクトル
上で書いたことすべてを行う,別の,おそらくもっと速い方法があります.手始めに,fe.060 を読み込み,この節の始めに説明したように較正を行います.次にファイル選択ダイアログを使って,残りすべてのデータを選択します.Preprocess タブをクリックして,fe.060 を基準に選択し,Mark, Align, そして :guilabel:`Set parameters`ボタンをチェックします.
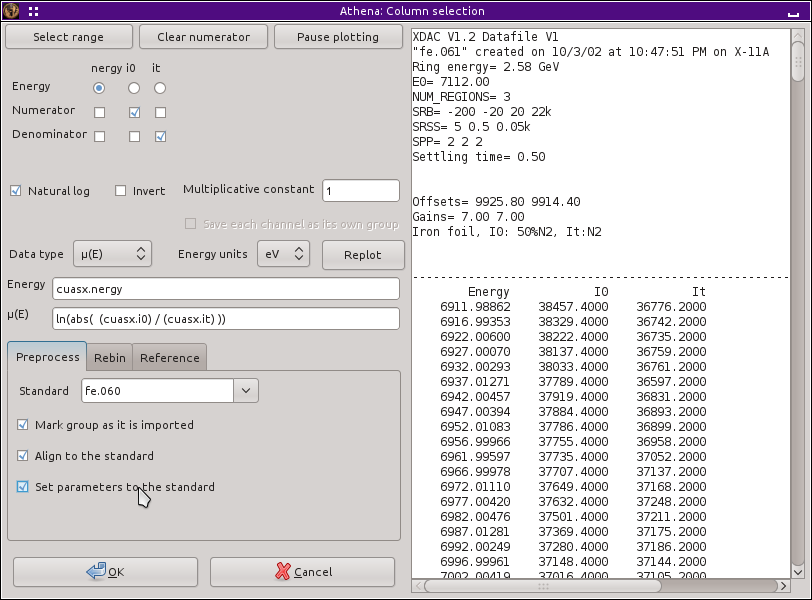
図 12.12 列選択ダイアログの前処理機能を使って,読み込みの際にデータの整列と束縛を行う
そして,Open ボタンをクリックしてください.残りのデータが読み込まれると,整列と «E0» の束縛がその場で行われ,新しいグループにマークがつきます.この前処理機能を使い,ファイル選択ダイアログが閉じると,ATHENA は上のスクリーンショットの様に見えるはずです.
この節の最後では,それぞれの温度で測定されたデータを マージ します.データは適切に整列および較正されているので,マージできる段階にあります.まず,マージしたいそれぞれのデータに印をつけます.以下のスクリーンショットで示しているように,300 K で測定された2つのグループにマークがついています. を選んでください.マージが実行され,グループリストに新しいグループが現れます. を選択するか,Alt-l と打つ,あるいは,グループリストの項目を ダブルクリックして,意味のある名前をつけてください.この処理をそれぞれの温度のデータに対して行ってください.
ついに,鉄箔のデータを解析し始める準備ができました!
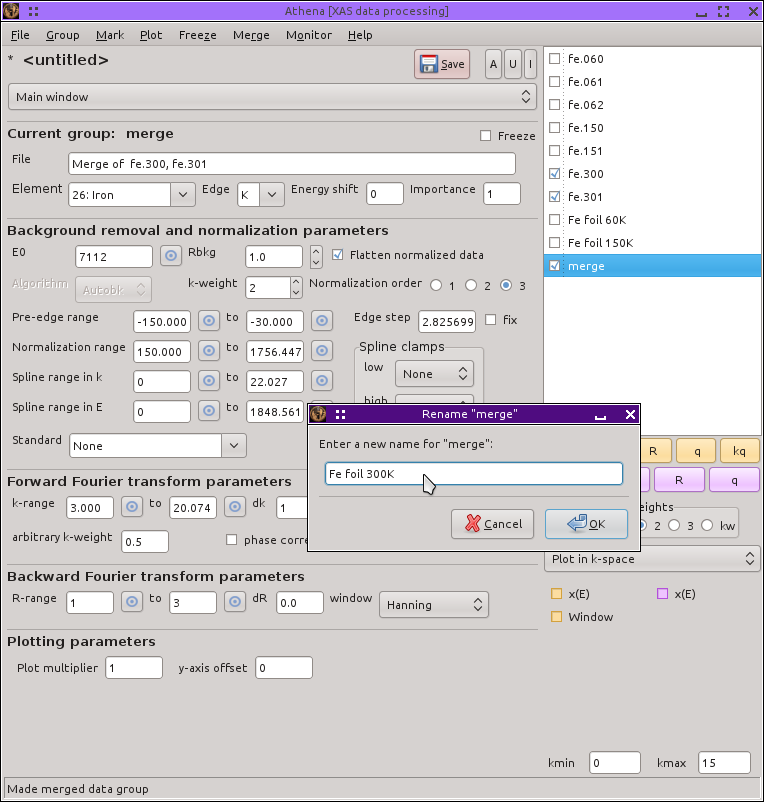
図 12.13 各温度で測定されたデータのマージとマージされたグループの名前の変更
DEMETER is copyright © 2009-2016 Bruce Ravel – This document is copyright © 2016 Bruce Ravel
This document is licensed under The Creative Commons Attribution-ShareAlike License.
If DEMETER and this document are useful to you, please consider supporting The Creative Commons.
