10.1. 線形結合フィッティング¶
10.1.1. データを標準物質の混合物として解釈する¶
ATHENA には未知のスペクトルを標準スペクトルの線形結合でフィッティングする機能があります.このフィッティングは規格化された μ(E),μ(E) の一次微分,あるいは χ(k) についておこなうことができます.この種の分析の利用例の1つは,還元反応中において測定された一連のスペクトルの速度論について解釈することです.それぞれの中間スペクトルを初期及び最終状態のスペクトルの線形結合としてフィッティングすることで,反応速度を求めることができるかもしれません.あるいは,混合試料について,どんな化学種がどれくらい入っているか決定するために使われることもあります.
線形結合による解析例は 後の方に 出てきます.
この機能を使うには,メインメニューから Linear combination fit を選択してください.通常のパラメータ表示が,線形結合フィッティングを行うための以下の図に示すようなツールに変わります.
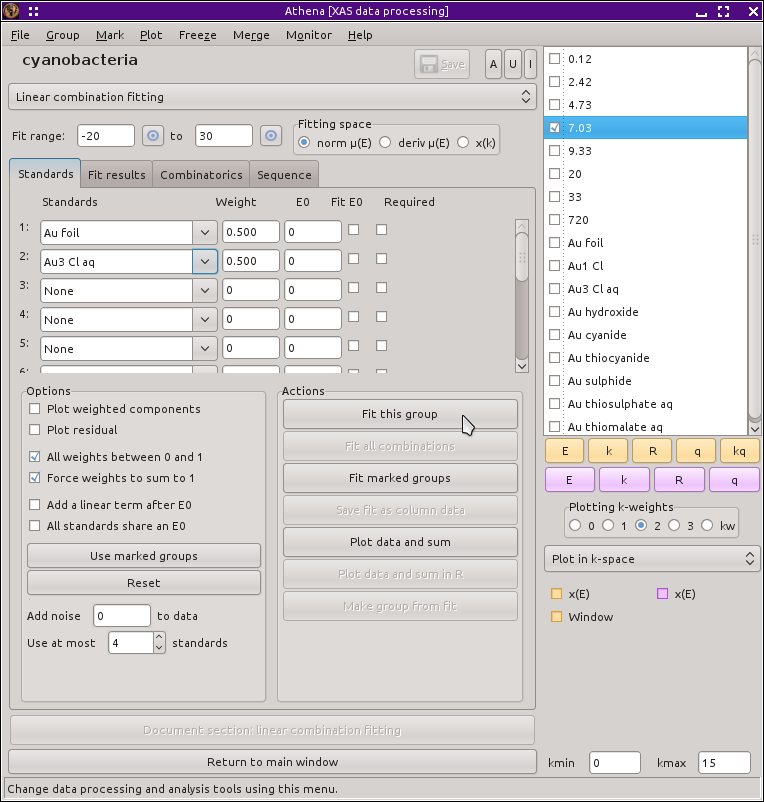
図 10.2 線形結合フィッティングツール
10.1.2. 1つのデータグループに対するフィッティング¶
線形結合ツールは,表のようなメニューになっています.これらのメニューはそれぞれ,データグループリストにあるデータグループからスペクトルを選択するために使われます.このツールにおける基本的な考え方は,2つかそれ以上の標準スペクトルを選択し,選択中のグループ(すなわち,データグループリストにおいて強調されているもの)に対して線形結合フィッティングを行うというものです.フィッティングは規格化された|mu| (E) スペクトルを使ってなされます.標準スペクトルあるいは未知のスペクトルが「フラット化」されている場合は,フラット化されたものが使われます.(フラット化されたスペクトルについては,バックグラウンド除去 に関する節を参照してください.)
事前に,標準試料および未知試料についてある程度のデータ処理を行っておく必要があります.特に,線形結合フィッティングを行う前に,それぞれのスペクトルについてデータの整列と適切な規格化パラメータを設定しておく必要があります.もし,適切なパラメータが設定されていなければ,フィッティング結果については疑問が残るでしょう.
フィッティングを行うために,それぞれの標準スペクトルに対して重み付けパラメータが設定され,リストの最後のスペクトルの重みについては,1 からその他の重みの合計を引いたものに,すなわち,標準スペクトルの合計が未知試料の 100% として束縛されることになります.よって,もし3つの標準スペクトルを使い,最初の2つの重み付けが x と y であれば,3つめは 1-x-y になります.x と y がデータに最もうまく合うように変動します.それぞれの標準スペクトルはフィッティングが規格化された μ(E) あるいは μ(E) の一次微分で行われる場合に,未知スペクトルのエネルギー軸に内挿されます.フィッティングはメインウィンドウの上部にあるテキストボックスで示されているデータ範囲で実行されます.近くにあるプラックボタンを使ってプロットウィンドウを  クリックすることで,フィッティング範囲を設定することもできます.
クリックすることで,フィッティング範囲を設定することもできます.
規格化された μ(E),μ(E) の一次微分,あるいは χ(k) のどれでフィッティングを行うかは,標準スペクトルの表のちょうど上にあるラジオボタンを使って選択することができます.χ(k) スペクトルでフィッティングを行う場合は,単一のスペクトルを使ってフィッティングを行うという選択肢を選択することができるようになります.
規格化された μ(E) あるいは μ(E) の一次微分スペクトルについてフィッティングする場合には,それぞれの標準スペクトルについて E0 を独立に動かすかどうか選ぶことができます.これは,それぞれのスペクトルについて,エネルギーについての整列が不十分な場合に何とかすることを意図しています(しかし,線形結合フィッティングを行う前にデータのを正しく行っておく方が遙かによいです.)これらの E0 変数は,標準スペクトルの表にあるチェックをつけることで有効になります.
規格化された μ(E) スペクトルにフィッティングする場合には線形のオフセットをかけることもできます.これは,単にフィッティングにおいて,スペクトルの和に対して直線を足すというものです.つまり,フィッティングにおいて,傾きと切片という2つのパラメータを導入します.直線は未知スペクトルの E0 を中心とするステップ関数でかけ算されます.よって,線形のオフセットは未知スペクトルの吸収端後のみに導入されることになります.このオフセットの目的は,すべてのスペクトルについて,規格化がどのように行われたかという変分をまとめ上げるようなものです.フィッティングの際に線形のオフセットを有効にするには,Add a linear term after e0? とあるラベルのボタンをクリックするだけです.
ご用心
最良の結果を得るには,線形結合フィッティングを行う前にデータの整列や規格化を正しく行っておく必要があります.規格化や整列が正しく行われていれば,フィッティングの重みの合計は 1 になると期待でき,標準スペクトルの E0 を変数とする必要はないでしょう.
10.1.3. フィッティングにおける束縛とオプション¶
ATHENA の線形結合ツールはフィッティングパラメータに対していくつかの束縛条件をつけることができます.この束縛条件は,画面の下部にあるチェックボタンで有効化,あるいは無効化することができます.
- 重み付けを 0 から 1 の間に制限
Weights between 0 & 1 とラベルされたボタンをクリックすることで,重み付け変数を 0 から 1 に束縛することができます.この場合,それぞれの重みは,以下の式を満たす変数として計算されます.
guess weight_varied = 0.5 def weight = max(0, min(1, weight_varied))
フィッティング後に報告される重みはこの式を満たすものになっています.但し,min/max のイディオムの利用は guess 変数が 0 か 1 になってしまった場合には偏差が計算できなくなるということに注意してください.これは,フィッティングに利用されている1つあるいはそれ以上の標準スペクトルがデータにとって適切でなく,フィッティングに使う標準スペクトルについて考え直した方がいいということを示唆しています.このオプションが選択されていない場合は,guess 変数それ自体がフィッティングにおける重みとして使われ,負の数になったり,1 以上になったりすることがあります.
- 重みの合計を 1 に固定
最後のチェックボタンの選択を外すことで,重みの合計を 1 にするという束縛条件を外すこともできます.その結果,最後のスペクトルの,合計が 1 に固定されていたときより自由に動かせることになります.この束縛条件をゆるめることでフィッティング結果の解釈が難しくなるかもしれません.もし,それぞれの重み付けが 0 から 1 の間になるという束縛条件下であれば,最後の標準スペクトルの重み以下の式で計算されます.
def weight_final = max(0, 1 - (w1 + w2 + ... wn))
これは,最後のスペクトルの重み付けを正の数にする効果がありますが,フィッティングにおいて,実際には合計が 1 にならないかもしれません.もし,そうなってしまったら,データの規格化が正しくない,あるいは標準スペクトルの選択がデータに対して適切でないことを示しているかもしれません.
- すべての標準スペクトルについて単一の E0 のシフトを利用
- フィッティングにおいて,すべての標準スペクトルに対して単一の E0 シフトパラメータを強制することもできます.これは,(見た目は違いますが)すべての標準スペクトルを固定して,未知のスペクトルに対して E0 シフト変数を使ってフィッティングを行うことに相当します.
- 未知スペクトルにノイズを追加
- ノイズの多いデータについて,フィッティングの安定性を確認することは時に有用です.特にいくつかのデータが他のデータに比べてノイズが大きい場合には.この目的のために,ATHENA ではフィッティングを行う前にデータに対して擬ランダムなノイズを加えることができます.これは,擬ランダムな数字の配列を生成してデータに対して加えることでなされます. もし,線形結合フィッティングにおいて,規格化された μ(E) が使われる場合,σ(ノイズのスケール) は単純に吸収端ジャンプ量に対する比率として解釈されます.適切なレベルのノイズを見つけるためには,何回か試行錯誤する必要があると思います.χ(k) に対するフィッティングの場合,ノイズは k の重み付けが行われる前にデータに対して追加されることに注意してください.データに対するノイズレベルをフィッティングを行う前に確認するには,アクションリストの中の Plot data and sum を使ってください.
- フィッティングにおいて線形の項の追加
- 傾きの変数とオフセットによる直線をフィッティングに加えることができます.この直線はフィッティングにおいて,E0 より後で評価されます.
10.1.4. フィッティング結果,統計,レポート¶
フィッティングを行うためには,アクションリストの Fit をクリックします.フィッティングが終わると,フィッティング対象のデータと線形結合の結果がフィッティングの評価に使われたデータ範囲を示す垂直の線と共にプロットされます.すべてのフィッティングパラメータの値は,Fit results タブに書き出されます.
線形結合フィッティングにおける統計パラメータの解釈は簡単ではありません.これには2つの理由があって,共にフィッティングが非線形最小二乗法によって行われていることに起因しています.
まず,XANES スペクトルにおいて独立な測定の数を数えることは困難(おそらく不可能)です.この数は測定されたデータ点数より少ないことは確かです.それでも,カイ二乗値を評価する際にはデータ点数が測定回数として利用されます.
次に,ATHENA には XANES 測定において測定誤差 ε を評価する方法がありません.カイ二乗の式において,ε として 1 が使われています.
この2つの問題が両方存在するため,カイ二乗値あるいは reduced カイ二乗値は1より遥かに小さなとても小さな値をとることになります.結果的に,reduced カイ二乗値をフィッティングの適合度として評価するのは不可能です.いくつかのフィッティング試行間におけるカイ二乗値の相対的な変化にはおそらく意味があります.しかし,上述の2つの問題のため,カイ二乗値は R 因子とあまり変わらない意味を持っています.
テキストボックスに表示される R 因子は以下で定義されています.
sum ( (data - fit)^2 )
------------------------
sum ( data^2 )
ここで,合計はフィッティング範囲におけるデータ点全体を示しています.カイ二乗値あるいは reduced カイ二乗値は IFEFFIT で計算された値です
統計パラメータの解釈には,測定している系について何を知っているのかよく理解しておくことが必要です.統計パラメータのみではフィッティング結果を評価するのに十分ではありません.試料の比率の結果は,系についてあなたが知っているほかの情報の元で意味があると言えます.
アクションリストの Plot をクリックすることで,一番最後に行ったフィッティングパラメータを使ってデータとフィッティング結果をプロットすることができます.
アクションリストの Write a report をクリックすることで,フィッティング結果のテキストデータをファイルに保存することができます.これによりフィッティング結果をヘッダー情報とした列形式のデータファイルを出力することができます.列はエネルギーあるいは波数 k の X 軸とデータ,フィッティング結果,残差,そしてそれぞれの重みのついたスペクトルです.
アクションリストの Make fit group をクリックすることで,線形結合フィッティングによって合成されたスペクトルのデータグループを生成することができ,Make difference group をクリックすることで,残差のデータグループを作ることができます. これで,線形結合ツールを離れてもフィッティング結果や残差をプロットしたり,さらなる処理を行うことができるようになります.フィッティング結果を含むデータグループはバックグラウンド除去やフーリエ変換などを通常のデータと同じように扱うことができます.微分スペクトルを使ってフィッティングを行った場合には,通常の|mu| (E) スペクトルとして保存されます.
アクションリストの Reset はツール内のほぼすべての項目を元の状態に戻します.
4つ以上の標準が必要な場合には,線形結合フィッティングにおける他の項目と同様に標準の数について,環境設定 で変更することができます.
10.1.5. バッチ処理¶
アクションリストの選択肢の中の1つに Fit marked groups があります.マークのついたグループすべてが,上述のように,その時点で使われている標準スペクトルやフィッティングオプションを使ってフィッティングされます.一連のフィッティングが終わると,operation リストにある:button:Write marked report,light が有効になります.これを使うと,一連のフィッティング結果をまとめた csv 形式のレポートを書き出します.このレポートファイルはどんな表計算ソフトでも読み込むことができます.
このレポートファイルはバッチ処理中に行われたフィッティング結果のみを反映することに注意してください.フィッティングモデルに変更があったとしても,次のバッチ処理が行われない限り,レポートファイルには含まれません.
また,バッチ処理と一連のフィッティングを個別に手で行うことの違いは,レポートファイルが生成できるかどうかだけです.今のところ,バッチ処理を行わずに一連のフィッティング結果から同じようなレポートを出力する方法はありません.しかしながら,上述の通り個別のフィッティング結果はいつでも出力できます.
10.1.6. 多数の標準による組み合わせフィッティング¶
この種の XANES フィッティングの用途の1つとして,ある試料中に実際には何が入っているかを見つけ出すという目的があります.このためのアプローチの1つとして,予想されるすべての標準化合物を測定し,標準スペクトルについて様々な異なる組み合わせでフィッティングを行うことが考えられます.ATHENA にはこの処理を自動的に行うためのツールがついています.どのように働くかというと,
- 線形結合ツールの標準スペクトルの表に,考慮に入れたいすべての標準スペクトルを入力します.場合によっては,設定ツールを使って,標準スペクトルの最大値を増やし,考慮したい標準試料すべてが入力できるだけの表が表示されるように変更する必要があるかもしれません.
- Use marked groups とあるボタンのすぐ下のボックスを使ってそれぞれのフィッティングにおける標準スペクトルの数を制限することができます.デフォルトではこの数は 4 であり,フィッティングの過程で 2 から 4 つの標準スペクトルのすべての組み合わせが検討されます.より多くの標準の組み合わせについて検討したければ,この数字を大きくしてください.逆にこの数字を小さくして,組み合わせの種類を減らすこともできます.また,標準スペクトルの表の右端にある “required” チェックボタンをクリックすることで,そのスペクトルを必須に設定することもできます.これで,設定されたスペクトルが組み合わせにおいて必ず含まれるようになるので,組み合わせの数を大きく減らすことができます.
- アクションリストの Fit all possible combinations をクリックしたら,コーヒーをいっぱい取りに行ってください.可能性のある標準スペクトルがたくさんあると,この一連のフィッティングはしばらくかかるでしょう.例えば,11種類の標準スペクトルについて,4つまでの組み合わせを考えるとすれば,ATHENA は 550 回フィッティングを行います.(つまり,C(11, 2) + C(11, 3) + C(11, 4) = 550! ということです)
一連のフィッティングが終わると,Combinatorics というタブがアクティブになって表示されます.このタブには2つの表があります.上の表は実行されたすべてのフィッティングについて簡潔にまとめられており,R 因子が小さな順に並んでいます.最初は,R 因子が最も小さいリストの最初の項目が選択されています.(つまり,薄い赤色で強調されています).
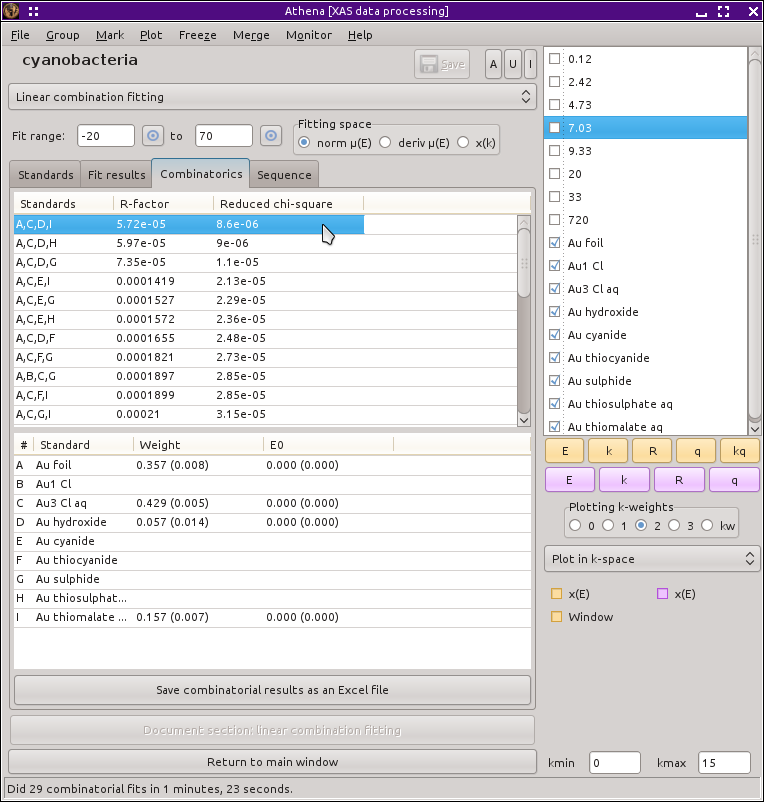
図 10.3 組み合わせフィッティング結果のタブ
2つめの表には,上の表で選択された結果について,それぞれの標準スペクトルとその重み付け,E0 が表示されています.
上の表から適当な行をクリックすることでフィッティング結果を選択することができます.そうすると,そのフィッティング結果が薄い赤色で強調され,結果が下の表に表示され,データと共にフィッティング結果がプロットされて他の2つのタブにその結果が表示されます.このように,一連の結果をプロットウィンドウで確認することができます.
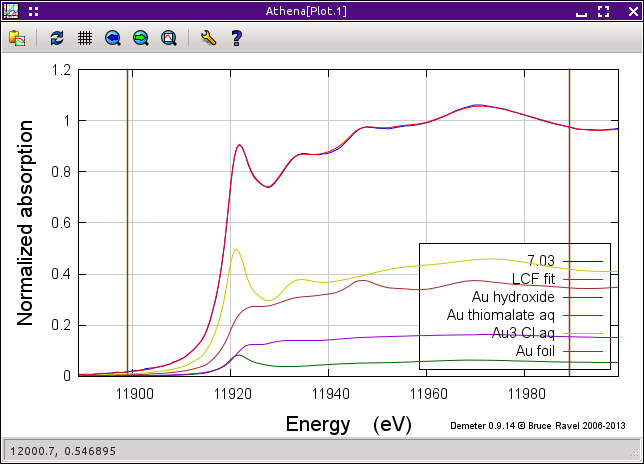
図 10.4 一連の組み合わせの最良のフィッティング結果
標準スペクトルの選択に応じて,2つあるいはそれ以上のフィッティング結果が同じような R 因子を示す場合があります.この結果は,これらのフィッティングが統計的に区別をつけることができないと解釈するかもしれませんし,これらの似たようなフィッティングから正しいものを選択するため必要な前提となっている知識を思い起こすかもしれません.リストの下にある他の結果は統計量からも結果のスペクトルからも明らかに悪いです.
上の表のフィッティング結果で右クリック  すると,選択された結果に関連する選択肢を含むコンテキストメニューが表示されます.これらの選択肢には,フィッティング結果をデータグループとして保存する,データ,フィッティング結果,残差とそれぞれの重み付きの標準スペクトルの列データを書き出す,Fit results タブからレポートをファイルに書き出す,あるいはすべての一連の組み合わせ全体を表計算ソフトにインポートできる csv 形式のレポートファイルとして書き出す,があります.
すると,選択された結果に関連する選択肢を含むコンテキストメニューが表示されます.これらの選択肢には,フィッティング結果をデータグループとして保存する,データ,フィッティング結果,残差とそれぞれの重み付きの標準スペクトルの列データを書き出す,Fit results タブからレポートをファイルに書き出す,あるいはすべての一連の組み合わせ全体を表計算ソフトにインポートできる csv 形式のレポートファイルとして書き出す,があります.
表の下には,Write CSV report for all fits ボタンがあります.これをクリックすると,ファイル名と場所を聞いてくるプロンプトが出てきます.その結果,すべてのフィッティング結果を含む CSV ファイルが保存されます.
線形結合による解析例は 後の方に 出てきます.
DEMETER is copyright © 2009-2016 Bruce Ravel – This document is copyright © 2016 Bruce Ravel
This document is licensed under The Creative Commons Attribution-ShareAlike License.
If DEMETER and this document are useful to you, please consider supporting The Creative Commons.
